
Introduction to BULK API 2.0
Bulk APIs are used in salesforce wherever there is a necessity to process large amounts of data. Usually, any data processing involving more than 2000 records should be an ideal situation to use bulk API. These APIs can be used to query, insert, update, upsert and delete Salesforce data. Bulk API 2.0 is more streamlined and simpler when compared to 1.0.
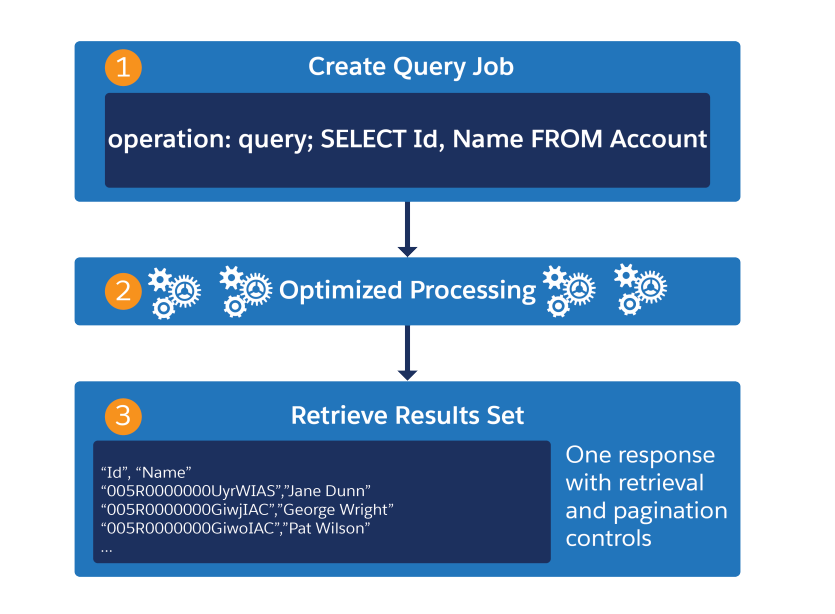
BULK API 2.0 query workflow example
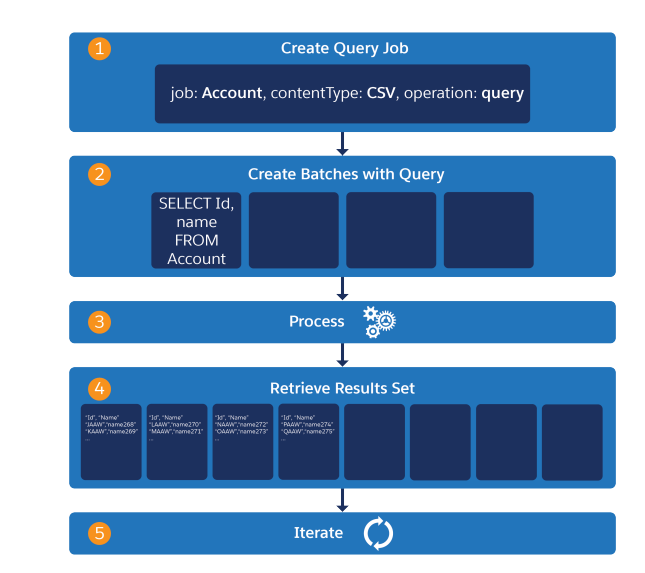
BULK API workflow is more complex.
Bulk APIs are based on REST principles and work asynchronously. When a query request is made these bulk API jobs automatically find the best way to divide the entire query result into chunks and send back each chunk. This avoids timeouts and gives you time to process the current chunk before the next chunk comes in(Detailed example below).
While ingesting data, salesforce creates a batch for every 10000 records and the maximum number of records allowed in a day is 150,000,000. Please find full details on how requests are processed here.
Let’s jump into a use case where we can use BULK API 2.0, how to request, process the data.
Use Case:
Assume you wanted to download all the opportunity records in the org as your company needed this information to process in an external system. Let’s deep dive into this.
The technical challenges involved here are opportunity records are in lakhs and you really can’t query all records by using normal SOQL query from the apex in one go, even though you use limit and offset, the maximum offset value that can be used is 2000 and any offset more than that gives NUMBER_OUTSIDE_VALID_RANGE error. Let’s solve all of these issues using bulk API 2.0.
Let’s start by creating a bulk API query call. We will first generate the call to retrieve data and download it later. Here is an example of how you can make this request.
HttpRequest Request= new HttpRequest();
Request.setMethod(‘POST’);
Request.setEndpoint(URl.getOrgDomainUrl().toExternalForm()+’/services/data/v50.0/jobs/query’);
Request.setHeader(‘content-type’, ‘application/json’ );
Request.setHeader(‘Authorization’ ,’Bearer ‘+userInfo.getSessionId());
String str_body = ‘{ ‘+
‘”operation”: “query”,’+
‘”query”: “select Name, Id from Opportunity “,’+
‘”contentType” : “CSV”,’+
‘”lineEnding” : “CRLF”‘+
‘}’;
Request.setBody(str_body );
Http http1 = new Http();
HttpResponse Response= http1 .send(Request);
Headers in the request should include Authorization and content-type headers. Authorization becomes easier as this request is made inside the salesforce. Just logged in user session-id will do the trick. This authorization will be different when these requests are made outside of the salesforce.
The body of the request should include content type (currently only CSV is supported), the operation should be “query” since we are retrieving data and the query includes the SOQL query we want to perform. LineEnding crlf mean Carriage Return which indicates end the line with ‘n’.
Response to this above request will be similar as below.
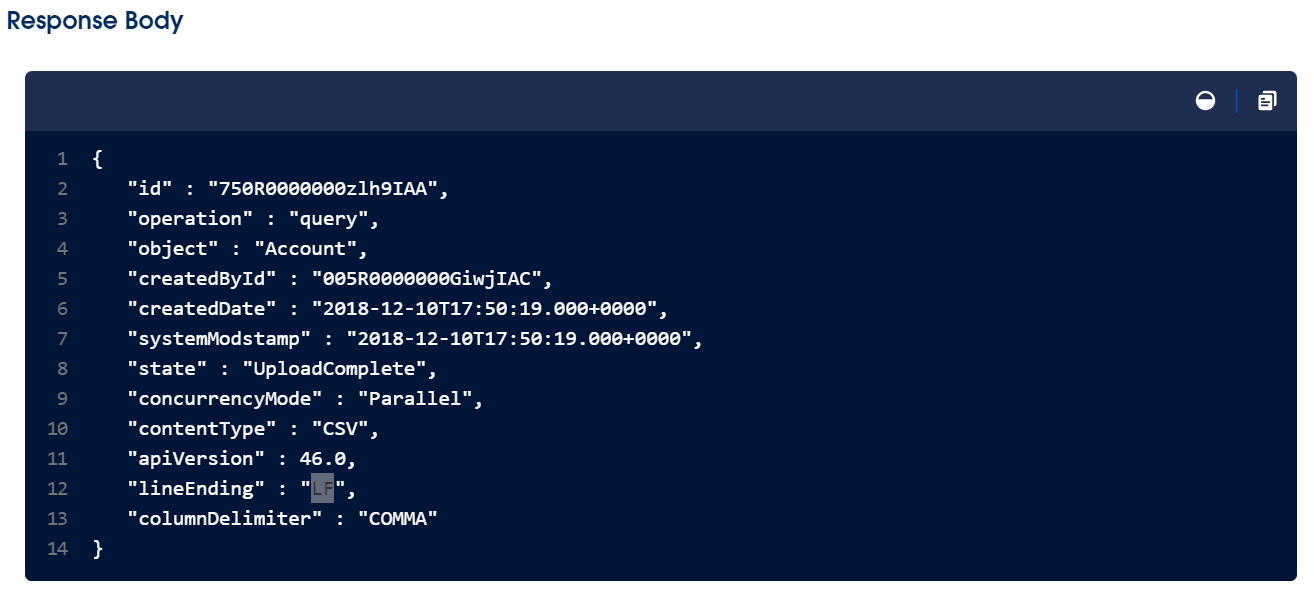
This request will not contain any data but it gives details about the asynchronous job. Data can be retrieved in the second step.
Response in this request includes a job Id which we have to store in order to retrieve data.
Map<String, Object> Map_response = (Map<String, Object>) Json.deserializeUntyped(Response .getBody());
String str_jobId = (String)Map_response .get(‘id’);
This request starts retrieving data in the backend but we have to perform another request to bring that data, which is our second step.
This second step involves making another HTTP request to retrieve data.
HttpRequest DataReq = new HttpRequest();
DataReq .setMethod(‘GET’);
DataReq .setEndpoint(URl.getOrgDomainUrl().toExternalForm()+’/services/data/v50.0/jobs/query/’+str_jobId +’/results?maxRecords=5000′);
DataReq .setHeader(‘content-type’, ‘text/csv’ );
DataReq .setHeader(‘Authorization’ ,’Bearer ‘+userInfo.getSessionId());
Http Http2 = new Http();
HttpResponse DataRes = Http2 .send(DataReq );
String str_ CSVBody = (String)DataRes .getBody();
String str_locator = (String)DataRes.getHeader(‘Sforce-Locator’);
The response body in the above request includes 5000 opportunity records in the CSV format which we are assigning to a string, along with headers which are field names in the query we requested. Now the request gives you only 5 records since in the request we specified it to retrieve only 5000 (maxRecords=5000).
Remember the lower value you give in maxRecords the more number of requests it takes to finish the entire request. There is another catch here, if you specify a maximum number of records to a very high number with more number of fields in the query there is a good chance timeout error can be encountered. So this number should be in a sweet spot where it should not be very high or low.
Since maxRecords values vary from one scenario to another. No finite range for this value.
In the response, one of the headers also includes “’Sforce-Locator’” which acts as OFFSET. Now in order to retrieve more records we have to use this Sforce-Locator.
HttpRequest DataReq2 = new HttpRequest();
DataReq2.setMethod(‘GET’);
DataReq2.setEndpoint(URl.getOrgDomainUrl().toExternalForm()+’/services/data/v50.0/jobs/query/’+jobId+’/results?locator=str_locator &maxRecords=5000′);
DataReq2.setHeader(‘content-type’, ‘text/csv’ );
DataReq2.setHeader(‘Authorization’ ,’Bearer ‘+userInfo.getSessionId() );
Http http3 = new Http();
HttpResponse DataRes2= http3.send(DataReq2);
str_CSVBody = (String)DataRes2.getBody();
str_locator = (String)DataRes2.getHeader(‘Sforce-Locator’);
Now when you use the locator from the second request it gives you another 5000 records continued from the first request. In other words, it gives you records from 5000 to 10000.
Since this HTTP request is considered a callout, consider callout limits.
Now similarly you will get this salesforce data until all your query resultant records are retrieved in chunks of 5000. Remember if you are using aura or lwc for this, after a certain point your page will become idle because when the data response comes in we are assigning that chunk of 5000 records to a string str_CSVBody and in the next callout we will assign another 5000 records to the same string. We are doing this because our ultimate goal is to download these records. Strings can hold data up to a certain limit and when you are dealing with lakhs of records we might hit that.
So a better practice would be to keep a count of the number of records that are added to the string and download the file after it reaches a certain number. Please find below the code to download records in the CSV file.
var blob = new Blob([“ufeff”,str_CSVBody]);
var url = URL.createObjectURL(blob);
var downloadLink = document.createElement(“a”);
downloadLink.href = url;
downloadLink .download = ‘OpportunityRecords.csv’;
downloadLink.click();
document. body.removeChild(downloadLink);
Reset the string after downloading and repeat the same. You might end up with multiple files but you will have all the records.
This example is for querying the records, for inserting the records endpoint URL changes to ‘/services/data/v50.0/jobs/ingest/’. Request body also changes. You can find details here.
Bulk API also has certain restrictions. Please find the entire limits here.
Link for more details regarding BULK API 2.0 – Click here
















